
There are few times when I'm so excited about a new feature that I'll write about it before multiple PRs are merged in multiple repos. Typically one would wait and have the patience until everything is fully merged to master yet I can't wait to talk about this one cause it's just too damn cool.
What this new branch offers is a way to instantly reboot cloud vms whenever your application dies a horrible death. Let's say a bunch of bad packets from the wrong side of town arrive and decide to shoot your vm full of lead. In a typical linux setup that instance is probably dead, Jim. Your load balancer might start re-routing around it. In a container setup you might get the same sort of deal. Sure, if it was just the process that died systemd might be configured to restart on failure but the whole box?
However, what if you weren't running a full blown linux as your base vm? What if your base vm was only a single application that your vm booted straight into and your application was re-spawned in seconds as if it was a process instead of a vm?
Enter the unikernel.
With this new branch you can literally kill the vm with a halt instruction and not only is your webserver alive again within seconds but it comes with a brand new memory layout.
I wasn't even thinking about this when this branch was opened but this is where the pull request turned from a 'nice to have' into a 'very interesting'. From an attackers perspective memory layout is everything. The ability to map out a program's memory layout is what makes almost all modern exploits work. ASLR (address space layout randomization) is one amongst many mitigations to deal with this.
So what happens if you get hit with a new memory layout on each and every HTTP request? This makes attacking the application *hard*. It's one thing if you are attaching gdb locally but on a remote system?
I consider this to be a 'killer' feature for unikernels in the cloud (and elsewhere).
So enough with the theory - let's get to the code...
If you're coming from the future then you can probably skip the next few steps but if you are reading this in January 2020 then please follow along.
Like I said none of this is merged yet so if you want to play on your own box you'll need to clone the Nanos repo and checkout this branch.
Also, since there is no corresponding pull in the OPS repo yet you can add this quick little hack to test it out with ops:
eyberg@box:~/go/src/github.com/nanovms/ops$ git diff
diff --git a/lepton/image.go b/lepton/image.go
index 0588c74..deb3ffe 100644
--- a/lepton/image.go
+++ b/lepton/image.go
@@ -231,6 +231,8 @@ func addFromConfig(m *Manifest, c *Config) error {
m.AddArgument(a)
}
+ m.AddDebugFlag("reboot_on_exit", 't')
+
for _, dbg := range c.Debugflags {
m.AddDebugFlag(dbg, 't')
}
This essentially toggles the feature on in the nanos unikernel manifest. The manifest has morphed throughout the past year and provides a stunning array of debugging toggles, filesystem layout, configuration and environment variables so OPS abstracts the hell out of it - there's definitely room for refactoring how this works.
Ok, back to memory layout and security. Let's look at the following code (and apologies I'm not a rustacean so please forgive any non-rusty things I might be doing).
fn main() {
let x = &42;
let address = format!("{:p}", x);
println!("{}", address);
}
We are essentially looking at the address of a stack variable, x. Normally on linux this memory location should change on each invocation of it's run. However, that is toggable via proc:
eyberg@box:~/xz$ cat /proc/sys/kernel/randomize_va_space
0
eyberg@box:~/xz$ ./main
0x55555557ae48
eyberg@box:~/xz$ ./main
0x55555557ae48
eyberg@box:~/xz$ ./main
0x55555557ae48
eyberg@box:~/xz$ echo 2 | sudo tee /proc/sys/kernel/randomize_va_space
2
eyberg@box:~/xz$ ./main
0x558fed52ce48
eyberg@box:~/xz$ ./main
0x564ead13ee48
Nanos has ASLR like functionality turned on by default and presently we don't offer the capability to turn it off (I believe some JIT'd langugages want it off) unless you build nanos yourself.
Let's deploy a little rust webserver to Google Cloud as a unikernel. Again, I'm not a practicing rust user so forgive me if I'm doing something stupid.
We start a small project:
cargo new hello_world --binThen we stuff this into our config.json:
{
"CloudConfig" :{
"ProjectID" :"my-project",
"Zone": "us-west2-a",
"BucketName":"my-bucket"
}
}
I'm using Google instead of AWS cause it's much quicker to deploy (less than 2 minutes).
This is my build script:
eyberg@box:~/r/hello_world$ cat build.sh
#!/bin/sh
cargo +nightly build
mv target/debug/hello_world hello-world
export GOOGLE_APPLICATION_CREDENTIALS=~/gcloud.json
ops image create -c config.json -a hello-world
You'll note that we need to use +nightly cause we're using inline assembly instructions to inject a halt.
This is my deploy script:
eyberg@box:~/r/hello_world$ cat deploy.sh
#!/bin/sh
ops instance create hello-world-image -z us-west2-a
#![feature(asm)]
use std::io::{Read, Write};
use std::net::{TcpListener, TcpStream};
use std::thread;
fn handle_read(mut stream: &TcpStream) {
let mut buf = [0u8; 4096];
match stream.read(&mut buf) {
Ok(_) => {
let req_str = String::from_utf8_lossy(&buf);
println!("{}", req_str);
}
Err(e) => println!("Unable to read stream: {}", e),
}
}
fn handle_write(mut stream: TcpStream) {
let response = b"HTTP/1.1 200 OK\r\nContent-Type: text/html;
charset=UTF-8\r\n\r\nHello world\r\n";
match stream.write(response) {
Ok(_) => println!("Response sent"),
Err(e) => println!("Failed sending response: {}", e),
}
unsafe {
asm!("CLI");
asm!("HLT");
}
}
fn handle_client(stream: TcpStream) {
handle_read(&stream);
handle_write(stream);
}
fn main() {
let listener = TcpListener::bind("0.0.0.0:80").unwrap();
println!("Listening for connections on port {}", 80);
for stream in listener.incoming() {
match stream {
Ok(stream) => {
thread::spawn(|| handle_client(stream));
}
Err(e) => {
println!("Unable to connect: {}", e);
}
}
}
}
Ok, so after we issue a request we not only kill the process - we kill the entire server. I left the server on overnight and as you can see some bots were sniffing around looking for random metasploit crap yet after each time we purposely kill it it's back to serving up requests. Remember - we aren't just restarting a process here - we are literally rebooting the server in seconds - let that sink in for a second.
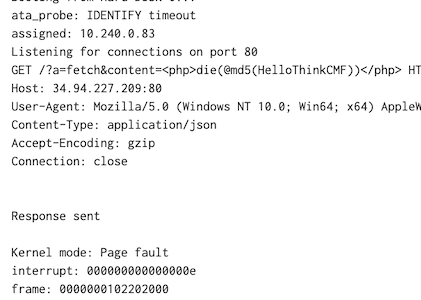
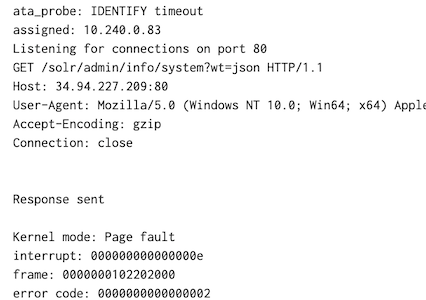
Being able to reboot not just an application but an entire server in seconds in response to an attack is a killer feature of unikernels.
