
It seems that all the cool companies are doing cross-region geo-routing for applications today. Many of them will label this as "edge". For someone like myself, edge usually means something different like having actual devices at sea, in the air, on a cell tower, in a Tesla, etc but if you are coming from the CDN world that translates to having multiple POPs (point of presence) spread throughout the world where you can host typically static sites (like javascript, css, etc.) closer to the end-user. Indeed many of the traditional CDN providers have evolved their offerings from hosting these static portions to running "edge functions" which provide some form of compute.
The whole idea is that it doesn't matter where in the world you live - you should get a snappy website load.
Companies like Vercel, Fly.io, Cloudflare (workers), Render, Supabase, and more are all advertising this. If you are more of a front-end dev this can make a lot of sense if your code is mostly static and you rely on external services for things like state.
I should point out - there is a massive caveat here. Things get a *lot* trickier when you want to manage state (read: databases) across the world. Hundreds to thousands of milliseconds is no laughing matter and presents real challenges even to companies whose sole existence is dedicated to distributed databases as any blogpost by Kyle will painfully point out. At a certain point you are fighting physics.
Anyways, let's sidestep the whole distributed data thing as that's not the focus of this article. Instead let's show you, dear reader, how you can replicate this "edge" functionality for your applications with unikernels so a user in Mumbai or a user in Santiago or a user in San Francisco can all enjoy local latency times - lan party style.
Note: If this is your first time playing around with unikernels you'll definitely want to check out ops.city first and run a hello world on your laptop and then run the exact same hello world on your infrastructure of choice (such as AWS or GCP) and that'll immediately answer many questions you have. As this is a more advanced topic start there first. I should also note that this takes almost no time at all - building ops.city, a go unikenel, on my laptop and deploying to prod takes less than 20 seconds.
Ok - back? Ready for the edge?
Now, there are very technical ways of going about achieving the desired goal here but keeping with our philosophy of doing the simplest thing that works we are going to spin up a load balancer. Unikernels really embrace the hacker ethos of KISS and eschew complexity over simplicity.
Luckily for us GCP can route to multiple regions at once and we can choose between HTTP(s) or TCP - there's no need to install something like Bird and manage it yourself - you're already on the cloud so just use what's there.
These load balancers use cold potato routing to limit the number of hops (eg: drive you to the nearest server) and utilize Anycast which basically allows multiple servers to listen to the same ip. So in actuality we don't have to do jack - thanks Uncle G!
So first things first let's create a load balancer. This provides a front-end ip that we could set a DNS record at for things like zero downtime deploys and then we point two instance groups at it for the backend:
Then we need to setup two instance groups. One in us-west2 and one in europe-west2. These should be in the same region as where you want to spin up the instances. I used unmanaged instance groups for this. Now I did this a little backwards as I spun up my instances first and then put them in instance groups but you should know that ops already has existing support for putting your instances into managed and unmanaged instance groups to scale them up on demand based upon load or error rate or whatever metrics you choose and this works fine on both AWS and GCP - no k8s necessary. I was trying to avoid using the k word in this article.
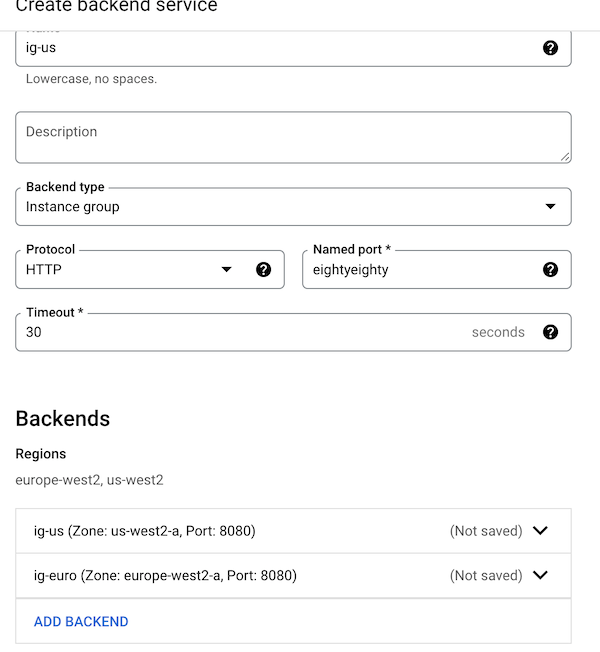
Our instance groups:
So let's create an image. If you've seen our tutorials before this is the same small little go webserver we use and since naming things is my forte I've just called the application 'region':
package main
import (
"fmt"
"net/http"
)
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Welcome to my website!")
})
fs := http.FileServer(http.Dir("static/"))
http.Handle("/static/", http.StripPrefix("/static/", fs))
http.ListenAndServe(":8080", nil)
}
GO111MODULE=off GOOS=linux go build
ops image create -t gcp -c config.json region
Then let's spin up two instances - one in each region:
ops instance create -t gcp -p 8080 -c config.json region
ops instance create -t gcp -p 8080 -c euro.json region
{
"CloudConfig" :{
"ProjectID" :"my-fake-project",
"Zone": "us-west2-a",
"BucketName":"nanos-test"
}
}
{
"CloudConfig" :{
"ProjectID" :"my-fake-project",
"Zone": "europe-west2-a",
"BucketName":"nanos-test"
}
}
Assuming we have the instances up, the instance groups up, and our load balancer up let's test it out by first pinging the instances themselves:
➜ region curl -XGET http://35.235.114.84:8080/
Welcome to my website!%
➜ region curl -XGET http://35.189.124.42:8080/
Welcome to my website!%
➜ region ping 35.235.114.84
PING 35.235.114.84 (35.235.114.84): 56 data bytes
64 bytes from 35.235.114.84: icmp_seq=0 ttl=247 time=15.485 ms
64 bytes from 35.235.114.84: icmp_seq=1 ttl=247 time=13.674 ms
--- 35.235.114.84 ping statistics ---
2 packets transmitted, 2 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 13.674/14.579/15.485/0.905 ms
➜ region ping 35.189.124.42
PING 35.189.124.42 (35.189.124.42): 56 data bytes
64 bytes from 35.189.124.42: icmp_seq=0 ttl=245 time=140.498 ms
64 bytes from 35.189.124.42: icmp_seq=1 ttl=245 time=139.670 ms
As you can see from my laptop one ip is within 15ms of me but the other one is across the US and across the Atlantic at 140ms away.
Now let's check the load balancer ip. You can see the new load balancer ip is responding very close to me:
➜ region curl -XGET http://34.102.163.201:8080
Welcome to my website!%
➜ region ping 34.102.163.201
PING 34.102.163.201 (34.102.163.201): 56 data bytes
64 bytes from 34.102.163.201: icmp_seq=0 ttl=58 time=7.211 ms
--- 34.102.163.201 ping statistics ---
1 packets transmitted, 1 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 7.211/7.211/7.211/0.000 ms
Now let's pop into London (a debian vm in europe-west2-a) for a quick pint to see what users in the UK might see:
eyberg@ian-region-test:~$ curl -XGET http://34.102.163.201:8080
Welcome to my website!
eyberg@ian-region-test:~$ ping 34.102.163.201
PING 34.102.163.201 (34.102.163.201) 56(84) bytes of data.
64 bytes from 34.102.163.201: icmp_seq=1 ttl=122 time=2.64 ms
64 bytes from 34.102.163.201: icmp_seq=2 ttl=122 time=1.89 ms
--- 34.102.163.201 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1002ms
rtt min/avg/max/mdev = 1.892/2.267/2.642/0.375 ms
Excellent! 2-3ms. Not too shabby. I'll show what the us-west2 ip was from this instance too just to show that Google isn't doing any internal routing to throw things off:
eyberg@ian-region-test:~$ ping 35.235.114.84
PING 35.235.114.84 (35.235.114.84) 56(84) bytes of data.
64 bytes from 35.235.114.84: icmp_seq=1 ttl=235 time=141 ms
64 bytes from 35.235.114.84: icmp_seq=2 ttl=235 time=139 ms
--- 35.235.114.84 ping statistics ---
3 packets transmitted, 2 received, 33.3333% packet loss, time 2003ms
rtt min/avg/max/mdev = 139.236/139.970/140.704/0.734 ms
As expected it responds in the time we would expect for a trans-atlantic voyage. You'll also notice that we've picked up some bad packet loss on our voyage across the ocean. Ouch.
Now you know how to do edge routing for your applications using unikernels nonetheless. What do you think? Should we make a tool to automate this more?
