
At first blush a cronjob sounds diametrically opposed to unikernels. The notion that you are going to execute a command, a set of commands or many sets of commands at various times throughout the day on an instance does seem to be contrasting, but just like other things in unikernel land we can abstract this concept out of our instance and into the cloud.
Cronjobs, whether or not they are labeled as such, are essential primitives for every organization. Whether it's the nightly email to marketing about DAUs or something that dumps gigabytes of data into parquet the idea of scheduling is everywhere.
There are many methods to run unikernel cronjobs. Nanos C2 has for quite some time had the capbility of running cronjobs - these get scheduled by a persistent service deployed as a unikernel that acts as the cron daemon - pretty straight-forward and simple.
Likewise if you are using NanoVMs Inception you can schedule unikernels on your inception machine using plain old cron. This is useful if you have requirements like running firecracker on AWS without having to resort to expensive metal instances or you need much tighter control over orchestration - perhaps your organization needs to integrate with kubernetes - Inception is a great way to run unikernels under k8s on normal ec2 instances.
At NanoVMs we believe the datacenter is the new computer and the cloud is the operating system and so that is why virtual machines need a new operating system built specifically for the cloud. (Also, "operating system" in this usage is not just marketing - it's an actual real operating system.)
Unikernel Payloads vs Normal EventBridge
Lots of people already use eventbridge to kick off lambdas and ECS tasks according to a schedule. How is that different from running a unikernel payload? There are plenty of differences - let's examine them.
LambdaLambda has a lot of issues. Right off the top - if you have a job that runs longer than 15 minutes you have issues. There are a lot of long running jobs like long running data pipelines that Lambda simply isn't cut out for. Not just long running jobs but things like the 10G memory limitation is rather bad for data intensive jobs too. Also you can't talk to a GPU through lambda which is increasingly not something that fits into many organizations today. Nanos has GREAT GPU support out of the box.
Finally, even though lambda is protected by a vm it still is running linux and is suspectible to all the issues that a general purpose operating system with mutliple user and multiple program capabilities introduce. We'll touch more on this in a second.
ECSECS uses containers which are inherently insecure. Fargate ECS does improve this but again, just like lambda you are stuck with linux. ECS is also a lot more expensive than running a normal ec2 instance. This is where unikernels come in. They are single application vms so there is no management or extensive configuration that you do like you would on a similar ubuntu/debian instance.
ECS also has memory overhead. ECS is also a lot more costly than the approach that I'm going to show you.
Fargate starts at $0.04048/vcpu/hr with spot at $0.0125. The t2.micro instance starts at $0.0116/hr with spot at $0.004. When you realize that both your ec2 workloads and ecs workloads are billed by the second with a min. of one minute duration unikernels immediately win.
Normal VMsYou might also suggest running a normal linux vm and using the actual cron daemon vs using eventbridge. A lot of people probably use this to begin with, however now you have to manage, secure and configure that instance. Raise your hand if you've ever had a box that was named 'cron' or had a 'cron' tag on it.
I can't tell you how many times I've had to recover a box where someone setup some poor mans logging on a cronjob, but didn't put in log rotation, let it run (or fail) and the logs ate through all the disk to the point that you couldn't even ssh in.
For the uninitiated - these unikernels are not just running something like alpine with the init set to your program. These are pretty different architecturally. They don't have the capability of running other programs. It's not just a heavy seccomp slapped on - it literally doesn't have the capability of running other programs including a shell or "commands" which are just another word for a program. There is a complete lack of a traditional interactive userland. While technically they are running the nanos unikernel you can view them more as single applications that are being ran.
Today we'll discuss yet another method of scheduling unikernels.
Using OPS and AWS EventBridge to Schedule Unikernels
To get started you'll need an IAM role that can assume the role for the event bridge scheduler looking like this:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"sts:AssumeRole",
"scheduler:*"
],
"Resource": [
"*"
]
}
]
}
At the very least you need to give it some EC2 access but if you want debugging capabilities SQS and Cloud Watch are good to have too. Cloudwatch metrics will allow you to see things like failed invocations - perhaps if the ami is missing or something, whereas the DLQ via SQS will allow you to have the full error statement if a schedule fails. We're still evaluating on how this might fit in cross-cloud but might have this as a toggable option for ops in the future.
To test this out we'll have a program that simply grabs the last top five submissions to HN latest. I've put in a sleep so we can see what happens, as this spins up, does the work and spins back down too fast:
package main
import (
"fmt"
"net/http"
"github.com/PuerkitoBio/goquery"
)
func main() {
res, err := http.Get("https://news.ycombinator.com/newest")
if err != nil {
fmt.Println(err)
}
defer res.Body.Close()
doc, err := goquery.NewDocumentFromReader(res.Body)
if err != nil {
fmt.Println(err)
}
icnt := 0
doc.Find("#bigbox .titleline").Each(func(i int, s *goquery.Selection)
{
if icnt < 5 {
fmt.Println(s.Text())
icnt++
} else {
return
}
})
time.Sleep(1 * time.Minute)
}
Since this is a program that just immediately starts vs a webserver that doesn't need to execute immediately you can also tell Nanos to slow down it's boot time:
{
"ManifestPassthrough": {
"exec_wait_for_ip4_secs": "5"
}
}
(Pro tip: Running Nanos workloads that are more persistent (eg: webservers) elsewhere you can use static ip instead of dhcp and have instant network w/out potentially waiting on dhcp.)
We can create the image and the cron using these two commands - all of which take mere seconds:
ops image create --arch=amd64 -c aws.json ctest -t aws
export EXECUTIONARN="arn:aws:iam::123456789012:role/cronjobtest"
ops cron create ctest "rate(1 minutes)"
Typically this might be followed by an instance create but for these workloads we use the cron create instead. Within a minute you should see your first instances coming online.
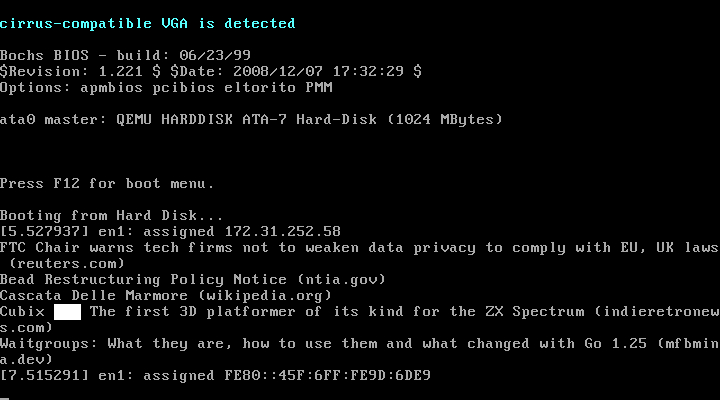
We print to serial here to showcase but in real life you'd be shipping any logs to cloudwatch or elastic or whatever logging setup you are already using.
Also, please don't forget to disable/delete this schedule if you are using the 1minute example - I'm just using that to show this functionality.
Scheduling unikernels on AWS is faster, cheaper, easier and way safer than using fargate ecs, aws lambda, or normal linux vms or containers. This is cloud native 2.0 cronjobs - powered by unikernels.
